목차
1. 시간복잡도 정의 와 몇가지 문제
2. 자료구조
(1) Stack and Queue 스택과
(2) Heap 힙
(3) Hash 해시
(4) Graph와 Tree 그래프와 트
(5) Linked List 링크드 리스트
3. 알고리즘
(1) Sort 정렬
(2) Recursion 재귀
(3) Binary Search Tree 이진탐색트리
(4) Round Robin 알고리즘
(5) DFS BFS
4. OS
(1) OOP 객체지향 프로그래밍 (다형성이란?)
(2) Singleton 패턴
ㄴ 싱글톤을 thread safe 하게 화이트보드에 구현해보라
(11) 옵저버 패턴
(3) DI
(4) RestAPI
(5) 프로세스 vs 스레드
(6) 데드락
(7) 스케줄링
(8) 메모리의 구조
(9) 컴파일로
(10) GC
ㄴ GC를 내가 직접 구현한다고 하면 어떻게 할 건지
(12) 1M 메모리에 1G 데이터를 정렬하려고 하는데 어떻게 해야 될까?
ㄴ 하둡, Map-Reduce
5. DB
(1) 트렌젝션
(2) Isolation level
(3) 정규화
(4) SQL 데이터베이스에서 언제 SCAN이 발생하는지
6. 네트워크
(1) TCP UDP
(2) 3 way handshake
(3) Http 요청과정
(4) HTTP 메서드가 하는 역할
(5) CORS를 해결하기 위한 헤더
(6) CDN이란 무엇인가
7. 개발 공통 개념
(1) 생성자란?
(2) 브라우저 랜더링 과정: https://jeong-pro.tistory.com/210?category=793347
(3) 객체지향
8. Java
(1) 접근제어자 차이
(2) 자바 스프링 개발자 면접 국룰: transaction, lock, isolation level, index, JPA N+1문제, DI, AOP, application context, 3 way hanshake, DI
(3) N+1 Query 문제
(4) JVM
(5) https://krksap.tistory.com/1136
(6) https://www.youtube.com/watch?v=Xk9z01AHEQ4
9. JS
(1) Async await가 Promise로 변환되는 과정
(2) Node v8이 비동기를 처리하는 과정
(3) ORM의 장단점
(4) HTTPS와 HTTP 통신의 차이
(5) lock 파일의 역할
(6) yarn vs npm
10. Pyhton
(1) self와 __init__의 기능
1. 시간복잡도 정의
입력이 증가할 때 연산량이 얼마나 빠르게 증가하는 지, 즉 '증가속도'를 의미한다.
참고로 공간복잡도는 연산에 필요한 램메모리 양
2. 자료구조
(1) Stack and Queue 스택과 큐
스택: last in first out 가장 최신 데이터를 먼저 보는 자료구조
큐: first in first out 들어간 순서대로 보는 자료구조
push하면 stack pointer++ 와 함께 데이터 저장
pop 하면 -- 하면서 데이터 출력,
sp가 0이면 null return stack size와 stack pointer가 같아지면 자동으로 늘려준다.
(2) Heap 힙
Priority Queue를 정렬하는 데에 사용되는 알고리즘. 우선순위가 높은 데이터를 먼저 보는 자료구조, O(logN)
최대힙(max heap) 부모가 자식보다 크거나 같은
최소힙(min heap) 부모가 자식보다 작거나 같은
삽입: 완전 이진 트리 모양. 마지막 노드에 input을 넣고 부모와 자식 노드를 비교하며 교환
삭제: root node 를 삭제하고 가장 마지막 노드를 그 자리에 넣고 다시 정렬
(3) Hash 해시
탐색 시간을 O(1)으로 혁신적으로 줄이는 알고리즘
어떤 데이터를 hash function을 통해 원하는 string으로 바꿈.
다만 해시테이블이 작다면 collision이 있을 수 있다.
(Probability Structure에서 어떻게 실제 사용되는 지 확인! ->링크)
(4) Graph와 Tree 그래프와 트리
무방향 그래프 , 방향그래프, cyclic graph ...
트리: 무방향, acyclic(loop 없는), 연결그래프(처음과 끝이 연결되어있지 않은), V개의 정점, V-1개의 간선(간선을 하나 제거하면 연결그래프가 아니게 된다, 독립된 node가 생기는 그래프) 동시에 간선 하나가 추가되면 cyclic해지는 그래프
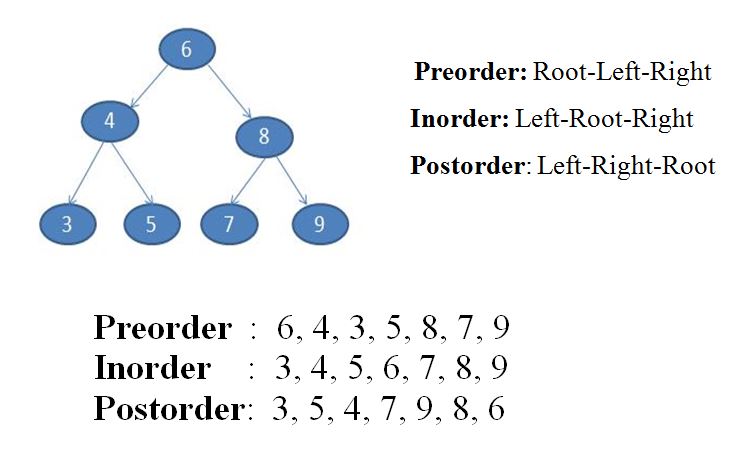
순회방식:
pre order: DFS, parent를 가장 먼저 count
in order: x 축을 기준으로 노드가 찍히는 순서대로 parent를 가장 먼저 count
post order: parent를 가장 마지막에 count
(5) Linked List 링크드 리스트
Array 에 비해서 InsertDelete를 O(1)으로 할 수 있다.노드의 head tail 부분의 주소값만 바꾸면 되기 때문이다.
또한 원형 리스트를 만들기에도 적합하고 양방향으로 binding을 하면 앞뒤로 탐색도 가능하다.
C++의 STL list 구현에 사용되고 대표적으로 메모장 문제가 있다.
(6) Trie 트라이
3. 알고리즘
(1) Sort 정렬
평균적으로 빠른 정렬: Merge Heap Quick
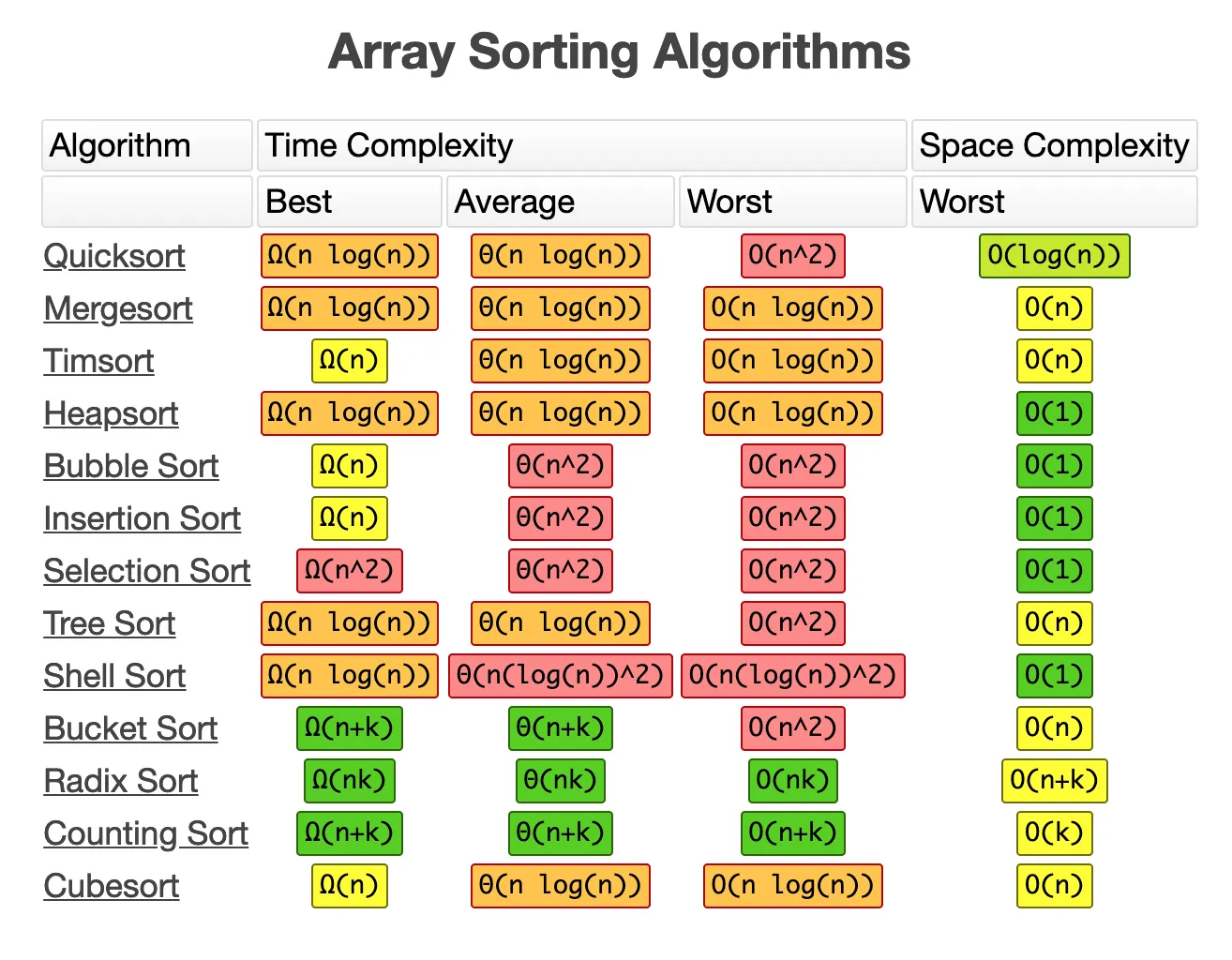
Merge Sort
가장 작은 단위까지 나눠서 합치면서 정렬하기

Quick Sort
원랜 기준값(pivot)을 기준으로 왼쪽은 작은 값을 넣고 오른쪽은 큰 값을 넣음
쉽게 말해 s는 pivot보다 작은 값을 찾으면 멈추고 e는 pivot보다 큰 값을 찾으면 멈춘다. 서로 바꾼다(swap)
e가 s보다 작아지면 pivot을 기준으로 작은/큰 크룹으로 나뉜다.
n번 반씩 잘라가므로(logN) 시간복잡도는 NlogN

Heap Sort
heap정렬을 이용해 정렬하는 것 NlogN
Tim Sort(Binary Insertion+Merge)
python, Java, Android, V8(chrome). swift에서 사용되는 sort
최선의 시간 복잡도는 O(n)O(n), 평균은 O(n\log{}n)O(nlogn), 최악의 경우 시간 복잡도는 O(n\log{}n)O(nlogn)
Insertion sort로 덩어리를 최대한 크게 만들어 병합 횟수를 최대한 줄이는 것
완전한 무작위가 아닌 실생활의 데이터의 특성상 증가하거나 감소하는 부분이 많을 것이고 이 원소를 한 번에 묶기 위한 작업이다
Tim sort에서 사용하는 Insertion sort는 Binary Insertion sort이다. Binary라는 용어에서 알 수 있듯이, 삽입해야 할 위치를 찾을 때까지 비교하는 대신, 앞의 원소들은 모두 정렬되어 있다는 전제를 기반으로 이분 탐색을 진행하여 위치를 찾는다.이분 탐색은 참조 지역성은 떨어지지만 한 원소를 삽입할 때 O(n)O(n)번의 비교를 진행하는 대신 O(\log{}n)O(logn)번의 비교를 진행하기에 작은 nn에 대하여 좀 더 시간을 절약할 수 있다.
Selection Sort
min 값을 찾아 정렬 안된 값과 swap

평균적으로 느린 sort: bubble, insertion
Insertion Sort
앞으로 진행하며 현재 값보다 작은 값이 나오면 다시 뒤로진행하며 값을 insert
(2) Recursion 재귀
(3) Binary Search Tree 이진탐색트리 (라이블로그)
이진 검색 트리는 이진 트리인데, 모든 노드가 다음과 같은 조건을 만족해야만 합니다.
① 왼쪽 자식이 있다면, 왼쪽 자식의 key 값보다 자신의 key 값이 커야 한다.
② 오른쪽 자식이 있다면, 오른쪽 자식의 key 값보다 자신의 key 값이 작아야 한다.
중위 순회를 하면 방문하는 순서에 따라 노드 값이 반드시 증가함을(감소하지 않음을) 알 수 있습니다.
(9-12-14-17-19-23-50-54-67-72-76)
항상 최적의 시간복잡도인 O(logN)에 근접하도록, 지닌 값들은 바꾸지 않으면서 그 형태를 변하게 해 스스로 균형을 맞추는 자가 균형 트리(balanced tree): 대표적으로 AVL 트리, 레드 블랙 트리, splay 트리, C++과 자바에 있는 set, map
(4) Round Robin 알고리즘: 들어온 순서대로 처리하는데 limit을 둬서 시간이 더 필요한 건 한 사이클을 돌고 나서 다시 이어서 처리하는 것.

4. 기타
(1) OOP 객체지향 프로그래밍 (다형성이란?)
(2) Singleton 패턴
클래스가 최초 한 번만 메모리를 할당(static)
'하나'의 인스턴스만 생성하여 사용하는 디자인 패턴이다.
최초로 생성된 이후에 호출된 생성자는 이미 생성한 객체를 반환시키도록 만드는 것
(java에서는 생성자를 private으로 선언해 다른 곳에서 생성하지 못하도록 만들고, getInstance() 메소드를 통해 받아서 사용하도록 구현한다)
메모리 낭비를 방지할 수 있다.
글톤으로 구현한 인스턴스는 '전역'이므로, 다른 클래스의 인스턴스들이 데이터를 공유하는 것이 가능
==> karma에서 browser로 테스트를 할 때에도 context를 유지시킨 방법. 실제로는 단 하나만 올라가져있다.
데이터베이스에서 커넥션풀, 스레드풀, 캐시, 로그 기록 객체 등에 많이 사용된다. Context를 공유해야하는 경우들
만약 싱글톤 인스턴스가 혼자 너무 많은 일을 하거나, 많은 데이터를 공유시키면 다른 클래스들 간의 결합도가 높아지게 되는데, 이때 개방-폐쇄 원칙이 위배된다.
결합도가 너무 높아지거나 closure 가 제대로 되지 않을 때 문제가 발생할 수 있다.
Java에서 사용할 때에는 holder에 의한 초기화를 사용한다.
JVM의 클래스 초기화를 이용함.
클래스 안에 선언한 클래스인 holder에서 선언된 인스턴스는 static이기 때문에 클래스 로딩시점에서 한번만 호출된다. 또한 final을 사용해서 다시 값이 할당되지 않도록 만드는 방식을 사용한 것
public class Something {
private Something() {
}
private static class LazyHolder {
public static final Something INSTANCE = new Something();
}
public static Something getInstance() {
return LazyHolder.INSTANCE;
}
}cf. JVM이란?
시스템 메모리를 관리하면서 자바 기반 애플리케이션을 위해 이식 가능한 실행 환경을 제공한다.
Byte Code 는 JVM 위에서 os상관없이 실행된다.
os에 종속적이지 않고 Java 파일 하나만 만들면 어느 디바이스든 JVM 위에서 실행 할 수 있다. JVM은 크게 Class Loader, Runtime Data Areas, Excution Engine, Garbage Collector 4가지로 구성되어 있다.
cf.
compiler: human readable을
JIT (Just In Time): JIT compilation is a feature of an interpreter for a given language 직접 사용하는 게 아니라 언어의 특성, 주로 dynamic/ loose typing을 가지고 있는 경우에 사용되는데 타입이 동적이면 미리 컴파일을 하기 어렵기 때문에... 실행하면서 그때마다 타입을 확인해서 적절하게 맞추는 것 -> Python(Pypy) 이나 JS
AOT (Ahead of Time): produce single native executable which you can then run.-> C++에서 컴파일에러나는 것, Go도 AOT로 되어있음
Interpreter( JIT 있거나 없거나 해서 intermediate representation 컴파일하는 interpreter)
human readable을 가져와서 bytecode로 바꾼다. -> 실행환경(execution environemtn에서 decoupling) JVM이 이렇게 byte 코드를 만들어서 환경에서 분리시키기 땜에 어느 OS에서든 사용할 수 있게 됨 =? cpython, java .net
이해가 명쾌하게 되었다!! 이영상 참고합시다
https://www.youtube.com/watch?v=5rn_MAspYFM
(3) IoC/DI
spring의 IoC(inversion of control)에 필요한 객체 메모리를 올려두고 그 인스턴스를 참고해서 기능들을 사용하는 것
객체의 life cycle을 다 관리할 필요가 없기 때문에 관리할 것이 적어진다!
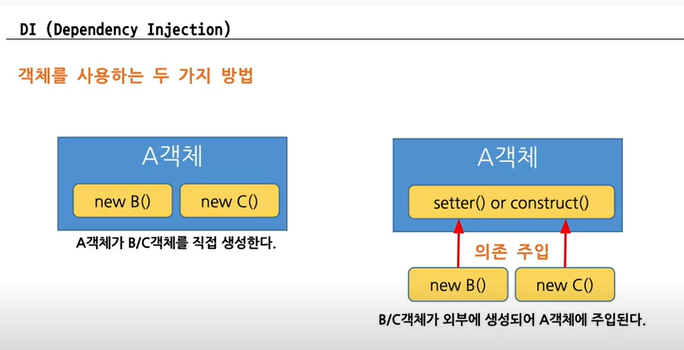
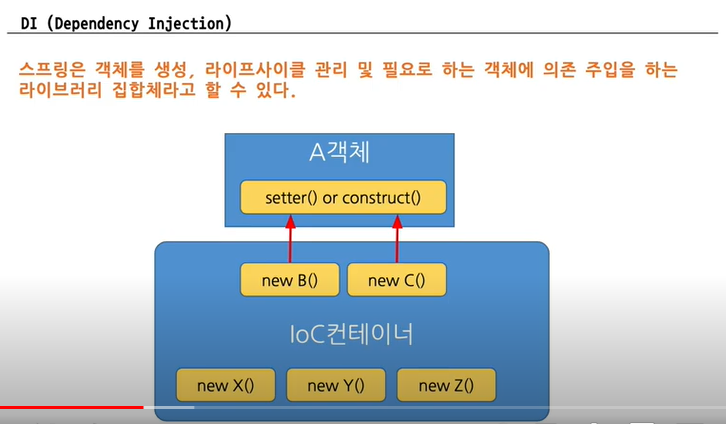
(4) RestAPI
프론트와 백엔드를 decoupling 시킴
요청 내용 자체가 자기 스스로 self-explanatory한 것.
HTTP method를 사용하기, query를 사용해서 url에 원하는 정보를 입력
VS
GraphQL
불러오는 정보가 유연해짐.
삭제나 업데이트는 보내는 요청에 updateClass deleteClass와 같이 적어서 함께 보냄
Rest API랑 graphQL을 동시에 구현해놔도 됨!
(5) 프로세스 vs 스레드
실행되는 프로그램의 메모리 단위, 스레드는 프로세스 안에서 실행되는 흐름의 단위
멀티프로세스는 두뇌가 여러개 있어야하고 ram에 올리는 context도 막 바뀐다.
멀티 스레드는 context를 공유하기 때문에 이런 스위칭이 일어나지 않는다.
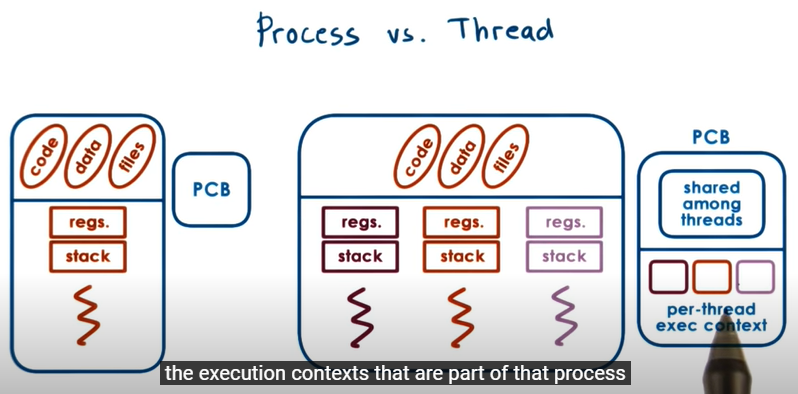
concorrency 랑 parallel을 비교하면
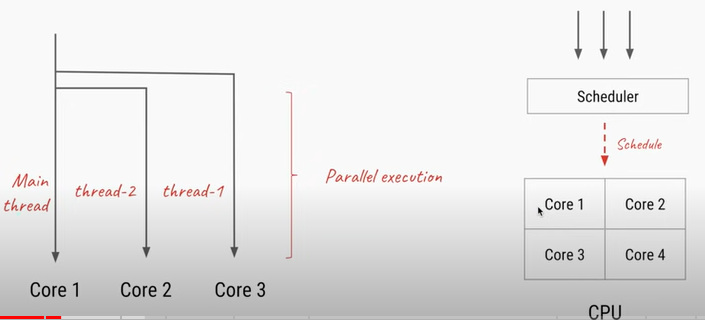
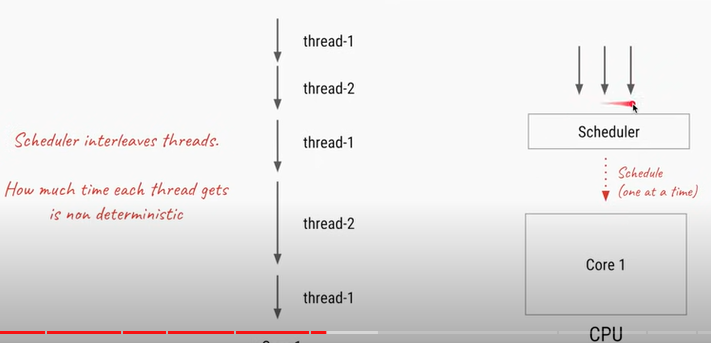
(6) 데드락
프로세스가 자원을 얻지 못해서 다음 처리를 하지 못하는 상태
교착상태
(7) 스케줄링
(8) 메모리의구조
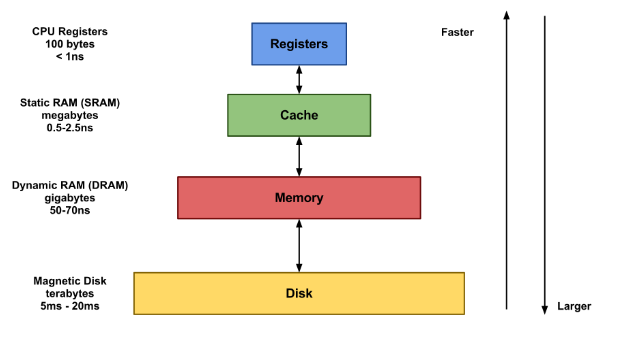
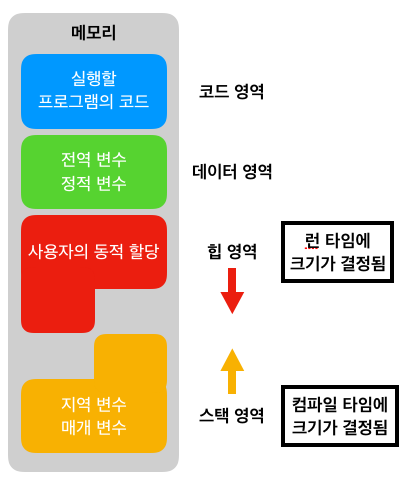
(9) 컴파일러
(10) TCP UDP
(11) 3 way handshake
(12) 트렌젝션
(13) Isolation level
(14) 정규화
5. DB
(12) 트렌젝션
(13) Isolation level
(14) 정규화
6. 네트워크
(10) TCP UDP
(11) 3 way handshake
7. 개발 개념
8. Java
(1) 접근제어자 차이 https://kephilab.tistory.com/58
public: OOP 제한, 클래스 외부에서 부를 수 있다
private: OOP 제한, 클래스 안에서만 접근
default: 별도 설정X 상태로 해당 패키지 내에서만 접근, 같은 집단위로만 접근
protected: 같은 package 안에서는 서로 접근 가능하고, 다른 package인 경우 같은 package에서 나온 자손이라면 다시 접근이 가능 한 것. 그러니까 따로 살아도 우리집 혈통이라면 우리집에 접근할 수 있는 것.
static: '전역'이라는 뜻, 공공시설
final: 한번만 초기화 가능한 것, 예: JS에서 const,
abstract: 매서드 선언부만 작성하고 구체적인 실제 수행은 implement로 구현
9. JS
10. Pyhton
최적화
async 로 성능을 향상시킬 수 있다면 어떻게 성능을 향상시킬 수 있을지?
- 코드가 더 리더블해진다. -> 콜백지옥에서 깊어지지 않는다.
- 순서가 보장되어야 하는 경우가 아니라면 병렬처리를 할 수 있기 때문에 병목현상 지점에서 하나의 해결방법이 될 수 있다. 큰 데이터를 batch 단위로 묶어서 비동기로 전송하는 경우 리턴 값을 확인해서 res가 없는 경우 재전송하면서 보완할 수 있다.
cuda의 의미
GPU에서 병렬처리하는 툴
CPU랑 GPU 차이
GPU는 단순연산 병렬처리에 강하다
regression classification 차이
연속성 있고 없고
[알고리즘] 시간복잡도 예제 15종 | 블로그 | 딩그르르
[알고리즘] 시간복잡도 예제 15종
dingrr.com
BST예시
heap -> priority queue(PQ)
GIL
global interpreter lock
멀티 쓰레딩이 불가능하다는 것
원래 멀티 코어라면 멀티 쓰레딩 시에 여러 개의 쓰레드가 여러 코어 상에서 병렬(Parallel) 실행될 수 있는데, Python에서는 그러한 병렬 실행이 불가능하다
GIL이 Python의 객체들에 대한 접근을 보호하는 일종의 뮤텍스(Mutex)
먼저, Python에서 모든 것은 객체(Object)이다. 그리고 각 객체는 참조 횟수(Reference Count)를 저장하기 위한 필드를 갖고 있다. 참조 횟수란 그 객체를 가리키는 참조가 몇 개 존재하는지를 나타내는 것으로, Python에서의 GC(Garbage Collection)는 이러한 참조 횟수가 0이 되면 해당 객체를 메모리에서 삭제시키는 메커니즘으로 동작하고 있다. 참고로, sys 라이브러리의 getrefcount() 함수를 사용하면 특정 객체의 참조 횟수를 알아낼 수 있다.
참조 횟수에 기반하여 GC를 진행하는 Python의 특성상, 여러 개의 쓰레드가 Python 인터프리터를 동시에 실행하면 Race Condition이 발생할 수 있기 때문이다. Race Condition이란, 하나의 값에 여러 쓰레드가 동시에 접근함으로써 값이 올바르지 않게 읽히거나 쓰일 수 있는 상태를 말한다. 이러한 상황을 보고 Thread-safe 하지 않다고 표현하기도 한다.
여러 쓰레드가 Python 인터프리터를 동시에 실행할 수 있게 두면 각 객체의 참조 횟수가 올바르게 관리되지 못할 수도 있고, 이로 인해 GC가 제대로 동작하지 않을 수도 있다는 말이다. 물론 이러한 Race Condition은 뮤텍스(Mutex)를 이용하면 예방할 수 있다.
뮤텍스(Mutex)란, 멀티 쓰레딩 환경에서 여러 개의 쓰레드가 어떠한 공유 자원에 접근 가능할 때 그 공유 자원에 접근하기 위해 가지고 있어야 하는 일종의 열쇠와 같은 것이다.
그런데 앞서 말했듯이, Python에서 모든 것은 객체이고, 객체는 모두 참조 횟수를 가진다. 따라서 GC의 올바른 동작을 보장하려면 결국 모든 객체에 대해 뮤텍스를 걸어줘야 한다는 말이 된다. 이는 굉장히 비효율적이며, 만약 이를 프로그래머에게 맡길 경우 상당히 많은 실수를 유발할 수도 있는 문제이다.
그래서 결국 Python은 마음 편한 전략을 택하였다. 애초에 한 쓰레드가 Python 인터프리터를 실행하고 있을 때는 다른 쓰레드들이 Python 인터프리터를 실행하지 못하도록 막는 것이다. 이를 보고 "인터프리터를 잠갔다"라고 표현한다. 즉, Python 코드를 한 줄씩 읽어서 실행하는 행위가 동시에 일어날 수 없게 하는 것이다. 그러면 모든 객체의 참조 횟수에 대한 Race Condition을 고민할 필요도 없어진다. 뮤텍스를 일일이 걸어줄 필요도 없어지는 것이다. 이것의 GIL의 존재 이유이다.
CPU 연산의 비중이 큰 작업을 할 때 멀티 쓰레딩은 오히려 성능을 떨어뜨린다. 병렬적인 실행은 불가능한데 괜히 문맥 전환(Context Switching) 비용만 잡아먹기 때문이다. 다음 예시 코드를 보자. 멀티 쓰레딩을 사용하니 오히려 더 느려진 걸 볼 수 있다.
하지만 GIL은 CPU의 연산 과정에서 공유 자원에 대해 발생할 수 있는 Race Condition 문제 때문에 필요했다는 걸 상기할 필요가 있다. 따라서 Python에서는 외부 연산(I/O, Sleep 등)을 하느라 CPU가 아무것도 하지 않고 기다리기만 할 때는 다른 쓰레드로의 문맥 전환을 시도하게 되어 있다. 이때는 다른 쓰레드가 실행되어도 공유 자원의 Race Condition 문제가 발생하지 않기 때문이다.
이러한 이유로, CPU 연산의 비중이 적은, 즉 외부 연산(I/O, Sleep 등)의 비중이 큰 작업을 할 때는 멀티 쓰레딩이 굉장히 좋은 성능을 보인다. 따라서 Python에서 멀티 쓰레딩이 무조건 안 좋다는 말은 사실이 아니다. 실제로, I/O 혹은 Sleep 등의 외부 연산이 대부분이라면 멀티 쓰레딩을 통해 큰 성능 향상을 기대할 수 있다. 다음 예시 코드를 보자. 멀티 쓰레딩을 통해 더 빨라진 걸 볼 수 있다.
일반적인 CPU 연산에 대하여, 병렬 처리를 하려면 크게 두 가지 방법을 생각해볼 수 있다.
먼저, 멀티 프로세싱을 이용하는 것이다. 한 프로세스의 여러 쓰레드들은 서로 자원을 공유하지만, 여러 프로세스들은 각자 독자적인 메모리 공간을 가져서 서로 자원을 공유하지 않기 때문이다. 물론 자원을 공유하려면 할 수는 있지만, 별도의 처리가 필요하다. 다만, 멀티 프로세싱은 메모리를 더 필요로 하고 문맥 전환의 비용이 꽤 된다는 단점이 있다.
다음으로, CPython이 아닌 다른 Python 인터프리터 구현체를 사용하는 것이다. 예를 들면 Jython 등이 있다. 그러나 흔히 사용하는 방법은 아니므로 권장하지 않는다.
GC
참고할만한 링크
https://sh031224.github.io/ask-for-information/docs/interview/backend
백엔드 | Ask for Information
본 문서는 직접 면접을 응시한분들이 작성하는 문서이며, 기업 보안 관련 문제에 대한 이슈가 발생할 시 해당 기업의 내용을 제거할 예정입니다.
sh031224.github.io
https://www.notion.so/44c16a0d16834917b75c70bec40797a3
안드로이드 면접 질문 정리
1. 자료구조
www.notion.so
https://it-eldorado.tistory.com/160
[Python] GIL (Global Interpreter Lock) 이해하기
이번 포스팅은 Python만의 특징 중 하나인 GIL(Global Interpreter Lock)의 개념에 대해 알아볼 것이다. Python 프로그래머라면 한 번쯤은 들어봤을 법한 용어지만, 정확하게 알고 있지 못한 분들도 많을 것
it-eldorado.tistory.com
https://it-eldorado.tistory.com/159
[Python] 비동기 프로그래밍 동작 원리 (asyncio)
JavaScript와 달리 Python은 비동기 프로그래밍에 어색하다. 애초에 JavaScript는 비동기 방식으로 동작하도록 설계된 언어인 반면, Python은 동기 방식으로 동작하도록 설계된 언어이기 때문이다. 그래
it-eldorado.tistory.com
'✅ Good Question100' 카테고리의 다른 글
| #003. 서버보안: 처음 서버를 샀습니다. 어떤 보안적 조치를 먼저 하시겠습니까? (0) | 2021.10.13 |
|---|---|
| (#001.비공개) 쿼리튜닝: MySQL이 요새 느리다는 신고가 들어왔습니다. 첫번째로 무엇을 확인하시고 조정하시겠나요? (0) | 2021.10.12 |
| #002. DB 이중화: 빡세게 동작하고 있는 MySQL을 백업뜨기 위해서는 어떤 방법이 필요할까요? (0) | 2021.10.12 |
