
목차
1. 문제상황
- 빡세게 동작하고 있는 MySQL을 백업뜨기 위해서는 어떤 방법이 필요할까요?
- 네트워크 에러로 인해 발생한 DB 서버 에러를 어떻게 해결할 수 있을까요?
2. 데이터 백업(MySQL)
3. DB Replica(DB 이중화) 개념, 종류, 작동방식
4. Multi Master DB 이중화의 개념, 종류, 작동방식
5. 총정리
1. 문제상황
Q1. 빡세게 동작하고 있는 MySQL을 백업뜨기 위해서는 어떤 방법이 필요할까요?
A. 데이터 베이스 이중화를 통해 MySQL을 중단하지 않고 데이터 백업을 뜰 수 있다.
Q2. 네트워크 에러로 인해 발생한 DB 서버 에러를 어떻게 해결할 수 있을까요?

문제를 조금 더 설명하자면... DB 이중화는 Master(이후 M) DB 서버가 다운되었을 경우 또 다른 M 이나 S(Slave 서버)가 작동해 서버 다운이 서비스 다운되지 않도록 실패 에러에 대비하는 것이다. 그런데 네트워크 에러가 나는 경우 DB 서버가 다운되지 않았음에도 에러 상황이라고 인식하게 된다. 따라서 M 서버 대신에 대신할 서버('failover 대상'이라고 한다)로 이관해야하는데 네트워크 에러다 보니 이것도 원활하게 진행되지 않으며 문제가 발생한다.
A. failover 발생시 DB 에러인지 네트워크 에러인지 확인하는 프레임워크를 사용한다.
2. 데이터 백업(MySQL)
MySQL을 기준으로 다음 키워드를 통해 MySQL 데이터를 백업하고 복원할 수 있다.
[ 직접 백업하는 방법 ]
백업
MySQLDump -u사용자 -p암호 DB이름 > DB백업.sql
테이블 백업: MySQLDump -u사용자 -p암호 DB이름 TB이름 > TB백업.sql
데이터 백업: MySQLDump -u사용자 -p암호 DB이름 TB이름 -w "조건" > 데이터백업.sql
복원
MySQL -u사용자 -p암호 DB이름 < DB백업.sql -- DB가 존재 하지 않는 경우 미리 생성 후 진행 하여야 함.
MySQL -u사용자 -p암호 DB이름 TB이름 < TB백업.sql
MySQL -u사용자 -p암호 DB이름 TB이름 < 데이터백업.sql
(출처: https://blog.naver.com/kilsu1024/110165190855)
[ Cloud 서비스를 이용하는 방법: AWS RDS 이용 ]
https://developer88.tistory.com/317
RDS를 복제해 주는 Replication 설정하기 #Master #Slave #AWS
AWS의 EC2를 확장할 때와 DB 서버를 확장할 때는 약간 다르게 접근해야 하는데요. RDS를 확장할 때의 전략중 하나가, 읽기 전용 서버들을 복제해서 부하를 분산시킬 때 사용하는 Replication입니다. 오
developer88.tistory.com
그런데 이렇게 백업을 하는 과정 중간에 INSERT나 DELETE 등 데이터가 수정이 되면 데이터 정합성(모순없이 일관된)을 보장할 수 없다. 따라서 백업을 처리할 때 데이터베이스는 Lock이 걸리며 DB의 트렌젝션이 중단된다. 그러니까 열심히 일하고 있는 DB에 일을 시키면서 동시에 백업을 할 수 없다.
이러한 문제를 해결하기 위해 데이터 이중화를 한다.
3. DB Replica(DB 이중화)
개념, 종류, 작동방식, 관리도구
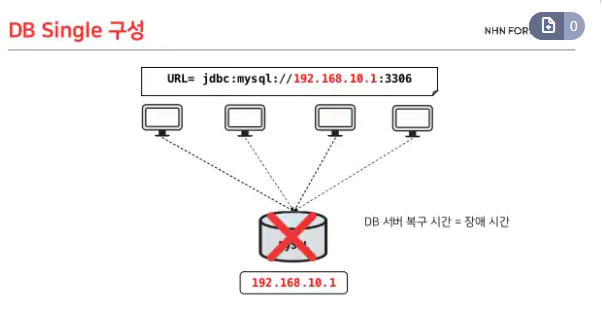

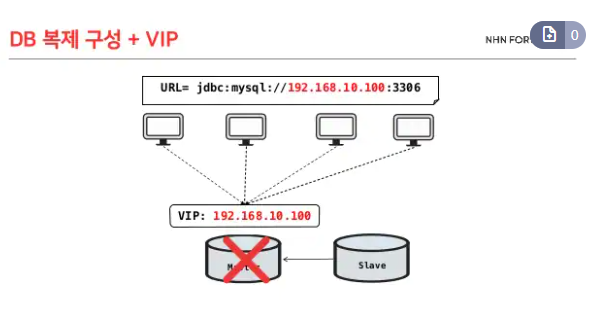
[ 개념 ]
DB 이중화란 두 대 이상의 DB에 데이터를 저장하는 방식이다. 위의 그림과 같이 하나로 구성되었을 때 백업이나 에러가 나면 그것을 처리하는 동안은 장애시간이 된다. 복제된 DB를 가지고 있다면 이런 상황에서 다른 DB 서버로 서비스를 이어할 수 있기 때문에 문제가 해결된다. 여기서 VIP (가상 IP , virtual IP)를 사용하면 IP를 바꾸지 않고도 서버를 바꿀 수 있다. ( AWS 클라우드에서 이러한 기능을 하는 서비스를 Load Balancer로 구현할 수 있다: AWS Load Balancer 글 링크)
[ 종류 ]
DB 이중화는 하드웨어적인 이중화와 서비스로 구현한 이중화 두 가지가 있다. 이 중에서 클라우딩 서비스에 더 집중해보려고 한다.
[ 작동 방식 ]


Slave가 하나인 경우Master의 로그를 Slave 로그에 복제한다. Master는 Client와 통신하며 들어오는 DML(Select, Insert, Update, Delete), DDL(Create, Alter, Drop, Truncate)를 Binary Log에 기록한다. Binary Log에 변화가 생기면 Slave 노드의 Relay Log에도 기록하고 Slave 노드 DB서버에도 같은 작업을 한다. 이 때, 복제 되었다는 것을 보장하기 위해 Binary에서 Relay로 ACK를 주고 받는다. Slave 노드에서 ACK가 돌아오면 Client로 OK response를 보낸다.
Slave가 여러 개인 경우도 비슷한데 Slave 중에 하나라도 ACK가 돌아오면 Client에 OK Response를 보낸다.
4. Multi Master DB 이중화
개념, 종류, 작동방식
[ 개념 ]
MMM(Multi-Master Replication Manager)는 이름에서도 알 수 있듯이 Master가 여러대로, Failover가 나는 경우 failover대상이 정해져있다(양방향 복제: 서로가 master이면서 slave이다). Monitor가 Agent를 통해 DB의 health를 확인한다.
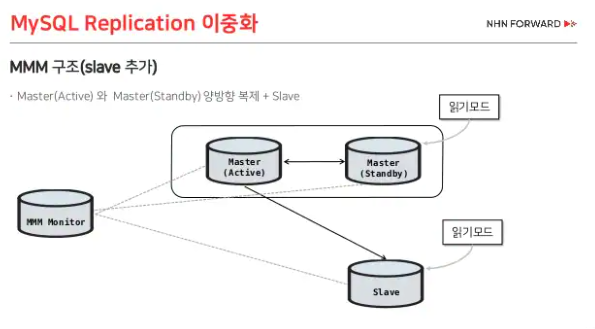
[ 작동방식 ]
정상적으로 작동할 때에는 Active한 Master를 제외하고 읽기 모드로 설정되어있다. 이 때 활성화된 노드에 장애가 생기면 이 노드를 -읽기 모드로 변경(데이터 보호) - Session Kill - VIP 회수(장애난 DB에 접속되지 않도록)를 한다. 그 후 Standby하던 Master에 복제지연이 없는 것을 확인했다면 이 Master를 Slave에 복제 시키고, Standby 였던 Master를 - 읽기모드 해제하고 이제 이 DB로 접속할 수 있도록 VIP를 할당한다. 그 후 Moniter에게 Failover가 완료되었다고 통신한다.
그런데 여기서 DB 장애가 아닌 네트워크 장애가 발생할 경우 위의 Q2와 같은 이슈가 발생할 수 있다.
DB 문제가 아닌데 Master와 standby master, slave에 접속할 수 없기 때문에 failover라고 인식되어 중복 replication으로 crash가 나거나 세션이 작업을 하지 못하고 그냥 사라지는 경우가 생긴다.

MHA (Master High Availability)로 이런 이슈를 해결할 수 있다. MHA는 1대의 Master로 구성되어 있고 failover가 났을 때 가장 최근에 업데이트 된 Slave DB의 권한을 승격시키고 나머지 Slave에 이 DB를 복제시킨다.
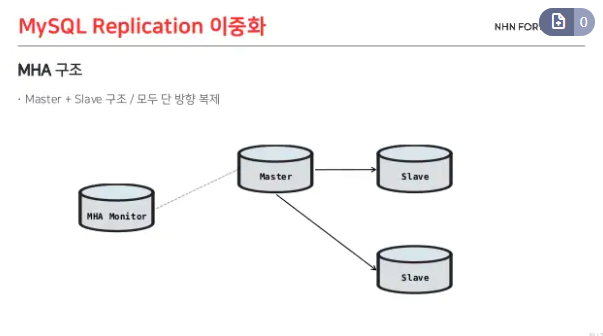

또 Master와 Slave가 각각 Log를 비교하는 방식이 아니라 Monitor 에서 중앙 집중적으로 비교해서 복제를 한다.

Secondary Health Check가 다르다. 이 기능은 failover가 날 때, 네트워크의 문제 때문에 발생한 것인지 확인해서 네트워크에 이상이 없다면 failover를 작동시키지 않도록 한다. (Q2의 문제 해결)

마지막으로 DNS 서비스를 지원해서 서로 다른 Zone에 있는 DB에도 데이터 복제를 가능하게 한다.
5. 총정리
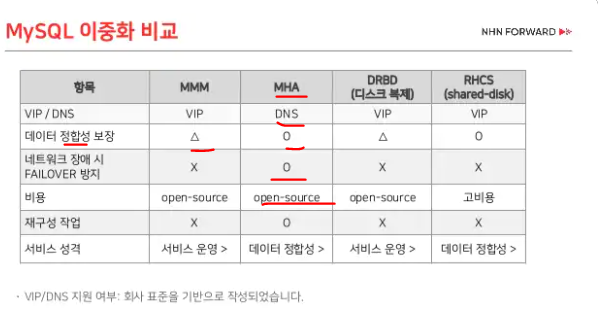
총정리를 하면, 서비스를 운영하며 무중단으로 데이터 백업을 하기 위해 데이터 이중화를 한다. 데이터 이중화는 백업 외에도 장애가 났을 때에도 서비스가 잘 운영되게 하는데, 대표적으로 MMM과 MHA 두 가지의 서비스가 있다. 서비스의 종류에 따라 데이터의 정합성이 더 중요하다면 Q2와 같은 문제를 해결하는 MHA를 적용시키고 단기간 서비스 운영에이 더 중요하다면 MMM를 사용한다.
데이터 사이언스 인터뷰 질문 모음집
데이터 사이언스 분야의 인터뷰 질문을 모아봤습니다. (데이터 분석가 / 데이터 사이언티스트 / 데이터 엔지니어) 구직자에겐 예상 질문을 통해 면접 합격을 할 수 있도록, 면접관에겐 좋은 면접
zzsza.github.io
https://www.youtube.com/watch?v=dCVKAJ7tb70
'✅ Good Question100' 카테고리의 다른 글
| 자료구조/알고리즘 인터뷰 준비 (0) | 2021.11.11 |
|---|---|
| #003. 서버보안: 처음 서버를 샀습니다. 어떤 보안적 조치를 먼저 하시겠습니까? (0) | 2021.10.13 |
| (#001.비공개) 쿼리튜닝: MySQL이 요새 느리다는 신고가 들어왔습니다. 첫번째로 무엇을 확인하시고 조정하시겠나요? (0) | 2021.10.12 |
